
这是一篇笔者在计算机学习中作的作业文章,综合了目前一些机器学习在出版业可能的应用方向。目前,虽然数字出版如火如荼,图书数字化已是初具规模,但是真正的将现代科技应用到出版的却是不多。本文在此希望能够将机器学习这样新的现代技术引入出版这个古老的产业,也希望两者能碰撞出一些新的火花。本文为英文写作,由于篇幅比较长,所以分三篇全文摘抄于此。
Machine Learning in Publishing Application
1 Introduction
1.1 Machine Learning and Publishing
Machine Learning at its most basic is the practice of using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world (Michael Copeland, 2016). Computers have many innate advantages over humans. Our computer/software is like a child with great memory and arithmetic skills, then machine learning is how to make this “smart” kid complete more work in more areas under our careful cultivation. Nowadays, with the development of artificial intelligence technology, computers have started to catch up with humans in the fields of pattern recognition such as speech recognition and image recognition. Computers not only can do a better job at machine translation, but they can beat humans in chess games.
Publishing, as a social activity of information dissemination, is a product of human society’s development to a certain stage. In the history of mankind, publications act as a very important recording tool and storage medium for human civilization. In the past thousand years, the dissemination of publications has greatly promoted the progress and development of science and technology, and similarly, the changes in science and technology have also profoundly influenced the development direction of the publishing industry (Srecko J. & Ivanka S., 2011).
Today, publishing and publications have changed dramatically from a thousand years ago. The carrier of publications has moved away from paper, bamboo, silk, sheepskin, etc., which have been used for thousands of years, to electronic paper, cell phones, and computers, and even to the Internet without a physical carrier. Likewise, publishing activities have seen tremendous changes, and on top of the traditional publishing model, we have a variety of publishing formats such as electronic media, online media, digital publishing, web publishing, and self-publishing. Under the influence of these new media, the way people read and get information is also changing. Publishing companies, large or small, that have been obsessed with paper publications for hundreds of years, suddenly find that they no longer dominate the market. In the last decade, what we discussed most in this field is like “Is traditional publishing dying?” or “Is traditional publishing dead?” At the same time, admittedly, everyone is looking for a different way out. Applying machine learning to publishing may be one such way forward for traditional publishing.
1.2 Machine Learning in Publishing
Most of the Articles or studies on the application of artificial intelligence and machine learning in publishing are analyzed from the perspective of the publishing profession. Ellen (2016) talked about machine learning in improving content creation & advertising. Max (2019) described eight ways that artificial intelligence can help traditional publishing better, like contracts, rights, royalty management, automated formatting, and content translation. Wang (2018) cited Artificial intelligence and big data technologies are penetrating all aspects of the publishing industry.
The author of this article worked as a book editor in a university publishing house in China for many years. The actual work as an editor does face the impact of technology on the traditional publishing industry. In this article, the author will discuss the possible applications of machine learning in publishing in the context of his own experience in book publishing, which focuses on three aspects: creating content (machine writing), helping the publishers, and connecting the publishers and authors.
2 Machine Writing
Machine writing can be traced back as far as the 1950s to research on machine translation. Currently, machine writing is not a very rare thing, and the biggest benefit of machine writing is to reduce the cost of content production (Xu W. & Wang J., 2019). If machine learning is introduced into content production, there are two ways: translation or pure creation.
2.1 Translation
Machine translation has been a major topic in the field of artificial intelligence since the 1950s. In recent years, machine translation has developed even more rapidly. Nowadays, translation software on the market is more or less influenced by artificial intelligence or machine learning, and or tech giants like Google, Microsoft, and Facebook are all making their effort to apply machine learning to translation. In 2018, Microsoft Research Asia and Microsoft Redmond Research have collaborated to achieve levels comparable to human translation on the Chinese-English translation test set of the Universal News Reporting Test Set WMT2017 (MSRA, 2018).
Take a translation software called DeepL, as an example. DeepL Translator is released to the public in August 2017, it is an online translator based on neural networks, offering free translations between English, German, French, Spanish, Italian, Polish, Dutch, Russian, Portuguese, Chinese, and Japanese. Due to the quality of the translation, more than half a billion people used its services in 2019. From the tests shown in Figure 1, DeepL has better translation results than the other competitors.
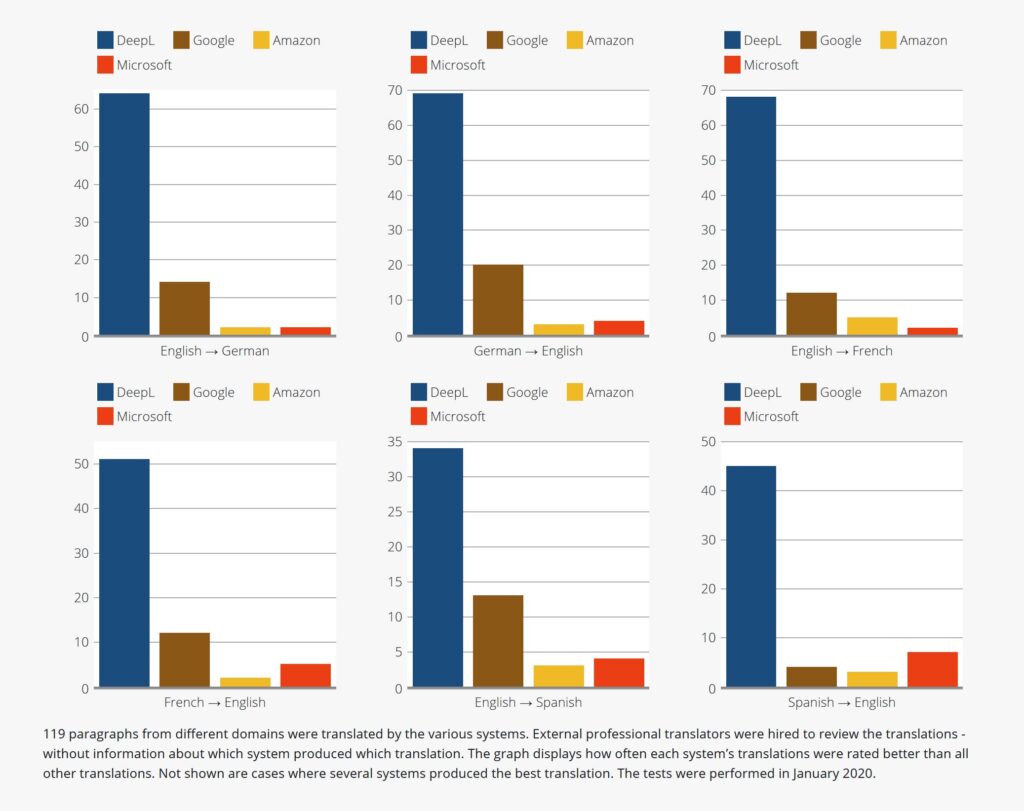
The introduction of machine learning will make translation software better and better in the future. If one day, machine translation could fully comparable to human translation, and we may encounter books that are completely translated by machines. Considering that machine translation may be faster and cheaper, future publishers of translation-focused books will be more profitable from machine learning.
2.2 Content Creation
The global journalism industries have undertaken attempts at machine creation regarding content production. In 2014, the Associated Press used WordSmith, an automated writing software, to write a large number of news stories based on analytics, including reading the content and following the framework provided by the editor. The New York Times’ machine writing program can assist in news production and publishing in 2 ways: first, by organizing data into the news; and second, by pushing breaking news to smartphone users. The Heliograf intelligence system used by The Wall Street Post, which uses artificial intelligence technology to edit news information and newsletters and post them automatically on Twitter. On March 17, 2014, an earthquake struck Los Angeles. An algorithmic program called Quakebot (Figure 2), written by Los Angeles Times journalist and programmer Ken Schwencke, automatically collected relevant information within three minutes of the earthquake and was the first to publish breaking news.
In 2008, Russia’s SPb publishing company published a fiction True Love. This fiction is a work of a computer program with a team of IT specialists. It is a variation of Leo Tolstoy’s Anna Karenina, but its word style is more like an imitation of Japanese author Haruki Murakami (Joshua, 2014). In early 2016, a short story When One Day a Computer Writes a Novel, a collaboration between artificial intelligence and humans, successfully passed the preliminary screening of the Nikkei Hoshi Shinichi Literary Award Ceremony in Japan. This fiction is from an AI project team at Future University Hakodate. The team first wrote a traditional novel to use as a template, then broke it down into words and phrases, and finally let AI do the work by learning and creating a selection matrix. At last, AI finished almost 20% of the work. Although it did not win any reward in the end, the fact that it passed the blind review by the professional jury had shown the potential of machine learning in creating novels (Rishi S. 2016). April 3rd, 2019, Springer Nature published the first machine-generated scientific book in chemistry: Lithium-Ion Batteries: A Machine-Generated Summary of Current Research. The book summarizes recent researches in the rapidly evolving field of lithium-ion batteries, and its content is an automated cross-corpus summary of a large number of existing research papers. In collaboration with researchers at the University of Frankfurt, Germany, Springer Nature has developed an algorithm called “Beta Writer” to select, use and process relevant publications in the field from SpringerLink, Springer Nature’s content platform, and they also strove to avoid human involvement in all aspects of the book’s creation: “With this prototype, Springer Nature has begun an innovative journey to explore the field of machine-generated content and to find answers to the manifold questions on this fascinating topic. Therefore, it was intentionally decided not to manually polish or copy-edit any of the texts so as to highlight the current status and remaining boundaries of machine-generated content.” “Our goal is to initiate a broad discussion, together with the research community and domain experts, about the future opportunities, challenges, and limitations of this technology.” (Beta Writer, 2019)
From the examples shown above, the news, novels, articles, and essays in the not-too-distant future, we can see a gradual shift from works created entirely by humans, to mixed human-machine-generated texts, and even entirely machine-generated texts.